

人財不足などの社会課題を背景に一層の業務効率化などが求められる中、自社業務に特化した生成AI活用が期待されている。これを受けて検索拡張生成「RAG」に取り組む企業も増えたが、「期待する回答精度には届かない、業務に使えない」という声は多い。どうすれば「想定した成果」が得られるのか。
製造や流通など、業種や分野を問わず人財不足が深刻化している。限られた人的リソースで業務を回すには、1人当たりの作業効率を高めるほかない。その課題を解決するためのキーテクノロジーが「生成AI」だ。
生成AIの活用効果はすでに広く認知されており、多くの企業が投資を進めている。だが、回答精度が低いなどの理由から「想定した効果が得られない」と頭を抱える企業は多い。そのような中で、人に依存するタスクの負担を軽減して人財不足を解消するための活用支援に乗り出しているのが日立製作所(以下、日立)だ。
自社を実験場として生成AI活用に取り組み、ノウハウや知見を蓄積し続けている同社に「成果を出す」ための具体策を聞いた。
「期待値に届かない生成AIの回答」その根底にある問題とは
「2024年、企業における生成AI活用は一段階進みました。代表的な例が、RAG(Retrieval-Augmented Generation:検索拡張生成)の利用です。しかし、RAGによって回答精度の向上を試みたものの期待したレベルに達していないというお客さまの声も増えています」。そう語るのは日立の橋本哲也氏だ。

橋本哲也氏(日立製作所 プラットフォームソフトウェア本部 生成AIサービス開発部 担当部長)
「精度が低いのは、言語モデル※自体に問題があるのでは」と考える人も多い。しかし、生成AIを業務にいち早く取り入れて検証してきた日立によると、「思うような効果が得られない本当の原因は、言語モデルだけではない」ことが分かってきたという。
※ここでは主にLLM=膨大な量のテキストデータを基に学習し文章等を生成する技術(GPT-4など)を含む自然言語処理を指す。
周知の通り、汎用(はんよう)的なLLM(大規模言語モデル)は多言語に対応している。議事録の要約や翻訳、アイデア出しといった一般的なフロントオフィス業務では、多くの企業がある程度手応えを得られるようになってきた。問題は、制御系システムや生産ラインの管理、ITシステムの運用、監視、トラブルシューティングといった今後ニーズが高まると予測される特定業務への適用だ。それには汎用LLMでは事足りず、一般的な知識だけでは解読できないデータや形式知化した暗黙知などの業務データも特定業務に特化したLLM(以下、業務特化型LLM)に取り込む必要がある。
しかし、機密情報を含む業務データを外部環境に出して学習させるわけにはいかない。とはいえ、そのままでは特定業務に即した回答は得にくい。その点、RAGは社内の情報に加えて外部の最新情報をソースとして利用することで回答精度の向上が期待できる。
これを受けてRAGに取り組む企業が増えたわけだが、単にRAGを利用するだけでは特定業務の用語や専門的な知識を理解させるのは難しい。専門的な問いに対する回答精度が低ければ、やはりLLM自体をチューニングする必要がある。公開されている学習データに自社独自のデータを追加して特定業務についての回答精度を高めるステップだ。
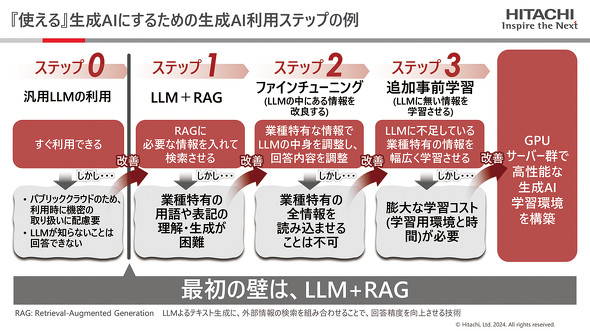
生成AI活用に向けた段階的なステップの例(出典:日立提供の資料。以下同)
前述した「思うような効果が得られない本当の原因」は、実はこうした「LLM+RAG」の前段階にあるという。日立の佐藤康文氏は次のように話す。
「そもそもLLMは自然言語モデルに過ぎません。期待するアウトプットを得るには、そのアウトプットを出すためのデータ(質問と回答)がセットでインプットされていることが前提です。明確な答えがない質問を投げかけられると誤った回答を出すハルシネーションが発生するのは、そういった前処理が欠けているためです。ここが生成AI活用の停滞しやすいポイントであり、制御系や製造の現場、顧客からの問い合わせに答えるコールセンターなどでPoCから先に進めない要因です」
LLMを補完するRAGを活用して、自社の知識やノウハウといった内部情報を集約したデータベース(以下、知識DB)に大量のデータを与えればいいかというと、そういうわけではない。ドキュメントやデータを与えるだけでは、生成AIが読み出して検索できる状態にはならないからだ。データパイプラインを整えて不要なデータは削除した上で、粒度や形式をそろえた知識DBを用意しなければ、大量のデータをいくら与えても期待する回答は得られない。
「目的に応じてどのようにデータを整備するか」も重要だ。システム運用に生成AIを活用するなら、「何らかの障害が発生したとき、どのような操作を行ったのか」という暗黙知をベテランのIT担当者にヒアリングして形式知化し、学習データとしてまとめる必要がある。これには、質問とそれに対する回答を障害のパターンごとに準備することが求められる。
「生成AIが使えない」を解決するための、日立の試行錯誤

佐藤康文氏(日立製作所 生成AIアプリケーション&共通基盤室 PJ推進部 部長)
このように、生成AIを特定業務で使いこなすまでには複数のステップとデータ整備という前提条件がある。だが佐藤氏は、「こうした課題に対して順を追って取り組むことで、『生成AIが使えない』という漠然とした悩みから、少しずつですが必ず解決策が見えてきます」と断言する。というのも、日立自身が生成AIの業務活用に取り組み、上記のような課題に直面しながら解決策を見いだしてきたからだ。
2023年、日立は全社で1000を超える生成AIのユースケースを抽出し、業務への適用を検証した。その結果、ソースコードのコーディングやレビュー、単体テストといったシステム開発業務、コールセンターのようなカスタマーサービスの領域で業務効率の向上が見込めると分かった。現在は、その結果を基に実業務への適用を進めている。
LLMを直接改良=ファインチューニングすることで、業務特化型LLMを構築する取り組みも進めている。実証実験のターゲットにしたのは、統合システム運用管理ソフトウェア「JP1」の2種類の認定資格試験「JP1認定エンジニア試験」「JP1認定コンサルタント試験」だ。生成AIにより正答率をどれだけ高められるか試したところ、ファインチューニングしたLLMだけの回答で認定エンジニア試験は90%、認定コンサルタント試験は58%まで正答率を上げられたという。認定コンサルタントは難易度の高い試験だが、RAGを組み合わせることでさらに合格ラインである正答率70%も達成した。日立はこうした検証を専門チームによって推進し、業務特化型LLMの構築とRAGの改良に関するノウハウを蓄積している。
その中で、回答精度の低さや不安定さに対しても、日立は数々の技術を開発している。ベクトル検索が苦手な「専門用語を用いた知識DB検索」を可能にする技術や、専門用語の表記揺れを自動的に修正するデータ前処理技術、複数のドキュメントを参照することで学習していない質問にも適切に回答する技術などがそうだ。このようにRAGを改良することでハルシネーションを抑制し、生成AIの回答をより模範回答に近づけることに成功したという。
さらに、誤回答の生成過程を分析、類型化してプロンプトエンジニアリングを組み合わせることで「回答精度を高めるツール」や、RAGに格納されたデータを整備する「データパイプライン構築を支援するツール」も開発した。RAGに使われている膨大なデータを収集して目的に合わせた形式に変換、ベクトル化してから格納するという一連の流れを効率化するものだ。これには日立のデータサイエンティストの知見が反映されている。
このように、数々の検証を通して培った技術により開発した精度の高い業務特化型LLMは、幅広い事業ドメインで生かされている。金融系のシステム開発担当部門は、人の代わりに設計書をレビューする業務特化型LLMを使ってレビュー工程に要する時間を削減。OT分野では、現場のエキスパートの暗黙知を取り込んでノウハウの継承につなげる取り組みを進めている。
業務特化型LLM構築を日立の技術と人で支援
社会課題の解決へ
こうした取り組みを基に、日立は2024年10月、「業務特化型LLM構築・運用サービス」「生成AI業務適用サービス」の提供を開始した。業務特化型の生成AI実現に向けて自ら課題を乗り越えてきた経験をサービスに生かす格好だ。
業務特化型LLM構築・運用サービスは、例えるならば「LLMの工場」だ。日立のノウハウをベースに、顧客の目的に応じて「どのようなデータを、どのような方式で学習させるか」をアドバイスし、業務に活用できる回答が得られるまでLLMの改良を重ねる。顧客のニーズに応じて、オーダーメイドで生成AI環境を構築する。
生成AI業務適用サービスは、業務特化型LLMや生成AIアプリの実行環境を提供する。クラウドはもちろん、LLM構築には大量のGPUリソースが必要となるためNVIDIAの最新GPUも用意。加えて、日立が強みを持つ次世代ストレージなどをAIインフラソリューション「Hitachi iQ with NVIDIA DGX」に搭載し、顧客の機密情報を保護しながら業務特化型LLMや生成AIアプリを安全に実行できる環境を整える。
もちろん「生成AIをどう活用すべきか分からない」といった課題にも応える。データサイエンティストや研究者の知見を生かし、目標設定から本番環境構築へと促す伴走型のコンサルティングサービスを用意。業務特化型LLM構築に必要なデータ整備から生成AI基盤やアプリの開発、運用フェーズに入った後の継続的な学習・改善まで、顧客と一緒に進めるという。
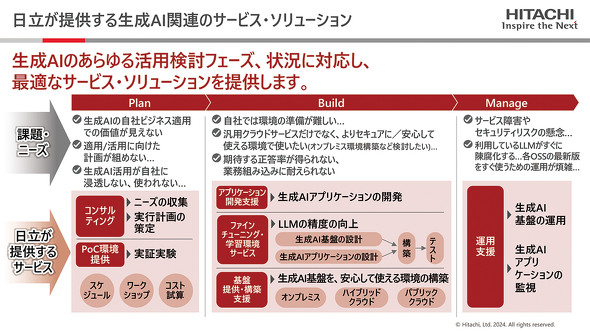
日立が提供する生成AI関連の支援サービスイメージ
日立ならではの強みは、LLMエンジニアやデータサイエンティストといった生成AI分野の専門家、ITやOT、プロダクトという各業務分野のプロフェッショナルを多数擁していることだ。
「当社には製造業や社会インフラ、制御システムを支える幅広い業務の専門家やエンジニアが在籍しています。どんなデータが必要で、どうチューニングすればいいか。経験値を積んだエンジニアが多様な業務ドメインで事細かに支援できます。業務特化型の生成AI活用に向けて、多くの皆さまの力になれると信じています」(橋本氏)

できることの可能性が非常に大きく、専門知識も求められるだけに、適用・実装のポイントや成果創出までのロードマップが見えなくなりがちな生成AI。日立は自ら試行錯誤して培った豊富な知見を生かし、多くの企業における生成AI活用を促進している。今後も、一連の取り組みを通じて人財不足という社会全体の課題に立ち向かえるように支援する構えだ。
●NVIDIAはNVIDIA Corporationおよびその子会社の米国その他の国における商標または登録商標です。
関連記事

関連リンク
ITmedia 2024年10月28日掲載記事より転載
本記事はアイティメディア株式会社より許諾を得て掲載しています
Digital for all. ―日立製作所×ITmedia Specialコンテンツサイト





